Using Screaming Frog as a beginner might be a very challenging task, since the tool offers many different settings, features and functionalities. The following tips are meant to provide useful shortcuts to save time and make working with the tool more effective and enjoyable.
1. Simulation of various crawlerbots
While crawling a site, using the specific user-agent of the desired search engines might be a good idea. So for example, when the target is to rank primarily on Google and see how this search engine specifically crawls the site, the bot should be set as Googlebot, in this case for Desktop.
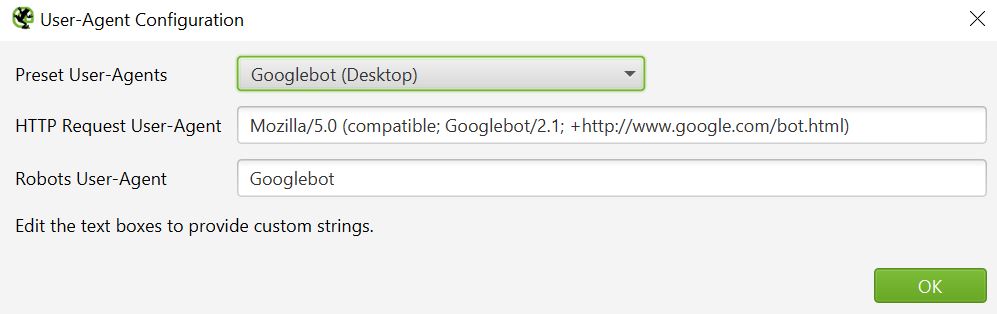
Configuration -> User-Agent
It is also important to note that when the SEO efforts are focused mainly on mobile devices, the user-bot should be set as Googlebot (Smartphone). There are many examples of various bots in the Screaming Frog settings, ranking from Bingbot to Seznambot so that the specific search engine bot can be always simulated as realistically as possible.
2. Bypassing the robots.txt file
Some sites are not fond of having random crawlers stalk their sites and therefore tweak the robots.txt files in the way that the bots are not allowed to enter the site structure. It might look something like this:
User-agent: Screaming Frog SEO Spider
Disallow: /
In order to try and bypass these settings, one can set the Robots Settings to Ignore robots.txt. This does not always work but is definitely worth trying as the first step in addition to having Googlebot as the default user-agent, since the majority of business sites allow Google to crawl their pages for obvious reasons.
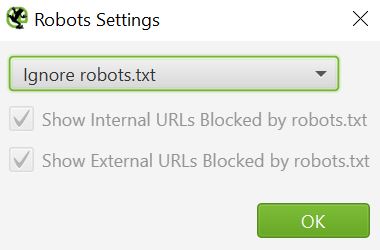
Configuration -> robots.txt -> Settings
If the above settings do not work, another addition might be using a custom HTTP Header, such as X-Forwarded-For with a known Google IP (66.249.66.1).

Configuration -> HTTP Header
3. Crawling a list of URLs
Sometimes, crawling the whole site is not necessary and having the possibility to upload a defined list of URLs might come in handy. Screaming Frog allows not only pasting the list manually but also uploading URLs from text files or directly from a dedicated Sitemap.xml link.
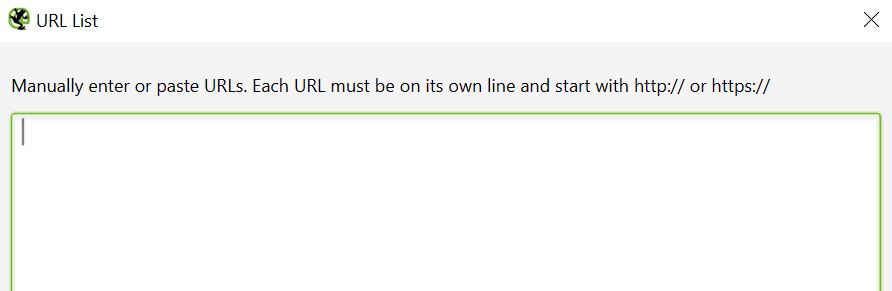
Mode -> List -> Upload -> Enter Manually
This option is particularly useful when you want to check outgoing links, status codes or metadata of specific pages.
4. Staying within one folder
Especially for large scale websites, crawl splitting is an important strategy and sometimes the only way to go through the most important pages without wasting computing power on unnecessary folders.
In order to stay within one folder, the box next to “Crawl Outside of Start Folder” needs to be unticked. The following picture shows the example of letting the crawl spread throughout the whole site without folder or subdomain restrictions.
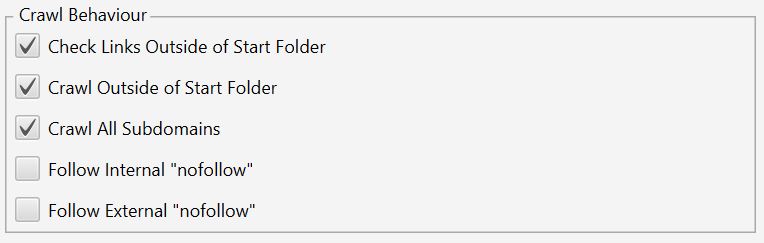
Configuration -> Spider
5. Visualising crawler paths
Sometimes the output given by the tool does not give a clear overview and provide actionable insights. The visualising options are a great way of displaying the site structure and discover any issues with the link flow distribution.
For example, when having only a few pages in one folder, it might make sense to merge them with other ones together.
Visualisations -> Crawl Tree Graph
There are many more tricks on how to make the work with the Screaming Frog tool more efficient and I will try to enrich the list with even more powerful tips in the future.

