In general, an SEO audit covers initial state and potential improvements in terms of the most important ranking factors – ranging from on-page, technical and (sometimes) off-page – with the goal of maximizing organic search traffic to the website. Together with the keyword research, site audit is the basic documentation output within the initiation SEO activities.
The main objective of the audit is not only to list recommendations, but above all to ensure their implementation in order to eliminate the issues. It is therefore necessary to prioritize individual activities based on the potential of increasing the ranking positions.
The sections below should be regularly checked and their status update should be definitely part of every SEO audit:
On-page SEO factors
The first section is usually the on-page ranking factors due to their relatively straightforward implementation possibilities and not needing to rely on any third party dependables. The only thing we need is (most of the time) just admin access.
Metadata optimization
The basic on-page ranking factor is the metadata, such as page title, description and headings (the rest like URL or images is covered separately below). The common issue with the metadata is usually related to duplications, missing or too long (or short) entries and absence of relevant keywords.

URL structure
The structure of URLs is another part of the metadata, however this one rarely changes due to high risk of losing rankings. Ideally, the URL structure should be determined before the site launch or in the early stages of operating. It is important to keep the URLs user friendly so that the reader can immediately assess and guess the content that will follow after clicking on the link.
Linking to 404s (not found) pages
Having broken links within the site’s content is usually a bad signal towards the crawler and should be fixed with a high priority. The issue is not their existence (there is an infinite number of 404s) but serving them to the bot as part of the crawlable content.
301s (moved permanently) in the redirection chain
Very similar to the previous point, 301 should not be a part of a redirected page. This can cause unnecessary delays resulting in longer page loading time and also discourage the crawler from further browsing the site.
Image sizes and ALT texts
Image sizes and ALT texts are also two established on-page SEO factors that are frequently checked during SEO auditing. The image size of individual images has a strong impact on the loading speed and therefore should not exceed 100kb. Regarding the ALT texts, they are important for being visible in the image search engines (e.g.Google Images) and also for the text-to-voice software input.
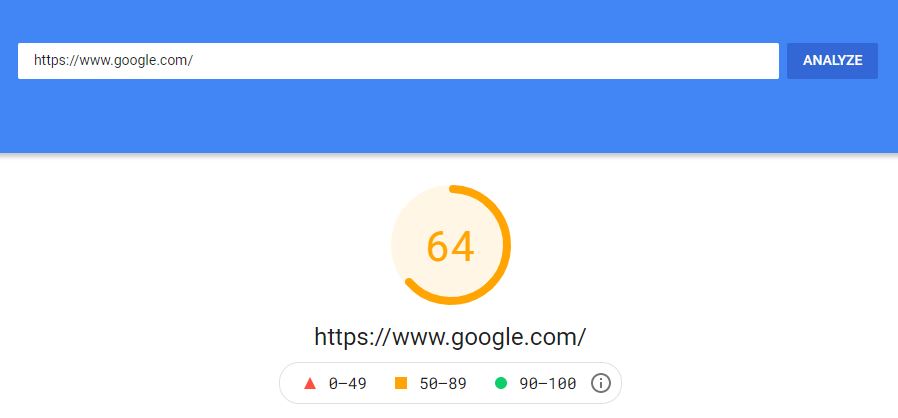
Page loading speed
As already mentioned, page load speed is a very important factor that significantly affects the performance in the search, especially on mobile devices. The loading speed is a key SEO element mainly due to the so-called mobile-first indexing which is being currently implemented by Google. Page loading can be checked for example in the PageSpeed Insights tool made by Google.
Duplications and canonical tags
From an SEO perspective, a duplicate content is content that targets identical or very similar user queries. Not having a clear primary page for a given keyword might confuse the crawler and result in cannibalization issues with multiple pages sharing competing for the same query. And since Google is trying to limit the number of multiple entries from the same domain in SERP, this might split the potential SEO power.
It is therefore recommended either to:
- Redirect the secondary page to the the primary one (to preserve the traffic and backlinks),
- Remove the page (in case of no traffic or backlinks),
- Canonicalize and merge both pages (to extend the valuable content)
Technical SEO
The recommendations in this section are mostly related to crawlers and technical settings, usually requiring some kind of code adjustments.
Crawling
Without ensuring that the bot can properly crawl the site and is able visit the right pages, no pages will be included into the search index. The most common issue is an incorrect robots.txt setup where the bot can get blocked from accessing the site completely. That is a common practice to avoid spying from competitors. In order to identify any inconsistencies with crawling, it is recommended to check the log files providing the complete journey of the bot through the site.
Indexing
Just as a page cannot be indexed without crawling, there will be no organic traffic without having the site indexed. However, not all pages need to be indexed and therefore it is recommended to leave out e.g. instances of shopping cart and other low value content for the user (such pages should also be left out from the sitemap.xml file). The indexation report is visible for example in Google Search Console or other third party tools.
Sitemap.xml
A sitemap.xml is a file that lives on its own URL (i.e. /sitemap.xml/) and helps the robot find important pages to index. As mentioned above, sitemap.xml should only display pages that contain valuable content for the user, i.e. password-protected or canonicalized URLs can be left out from the file.
Robots.txt
The robots.txt text file also lives on its own URL (i.e. /robots.txt) and says which robots (such as Googlebot or Ahrefsbot) can access the site or specific subfolders. In general, the robots.txt rules serve mainly as a recommendation, however most of the bots respect the settings.
Off-page SEO factors
The backlink analysis is sometimes treated as a separate document, however it is contextually also part of the SEO audit. The most common off-page factors that are included in this section are for example number of backlinks and referring domains, domain authority, topical relevance of linking sites, Trust Flow and Citation Flow metrics, distribution of referring ccTLDs, link profile toxicity, anchor text ratio and blackhat tactics detection (e.i. PBNs or negative SEO campaigns).

